
지난 시간엔 검색 엔진이 무엇인지 살펴봤고 이번 시간엔 검색 엔진의 작동법에 대해서 설명해드리겠습니다.

웹페이지는 글, 그림, 영상 (멀티미디어), 혹은 기능들로 구성 되어있습니다.
Google SERP의 구성
- 검색창 (Search Query Box)
- 네비게이션
- 검색수 (Search Results)
- 유료 광고 (Google Adwords PPC 광고)
- 구글 검색 결과 1
- 구글 검색 결과 2 (Organic Search Results)
위의 내용들이 기본적인 검색 결과 입니다. 하지만 때때로 다른 검색 결과들을 노출시켜줍니다.
- 지역 사업 정보
- 날씨 정보
- 인물 정보
- 행사 정보
- 사건 정보
구글 스파이더맨
구글 검색 엔진은 어떻게 작동하는가? 구글 검색 엔진 관련 특허들 확인하기
Link Structure가 중요 - 구글 알고리즘 특허 클릭하기
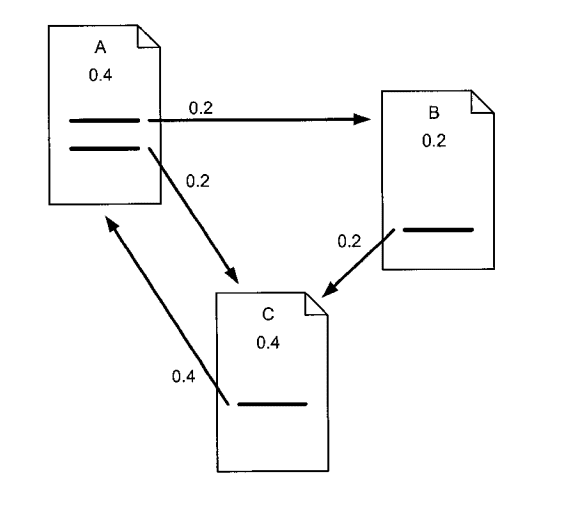
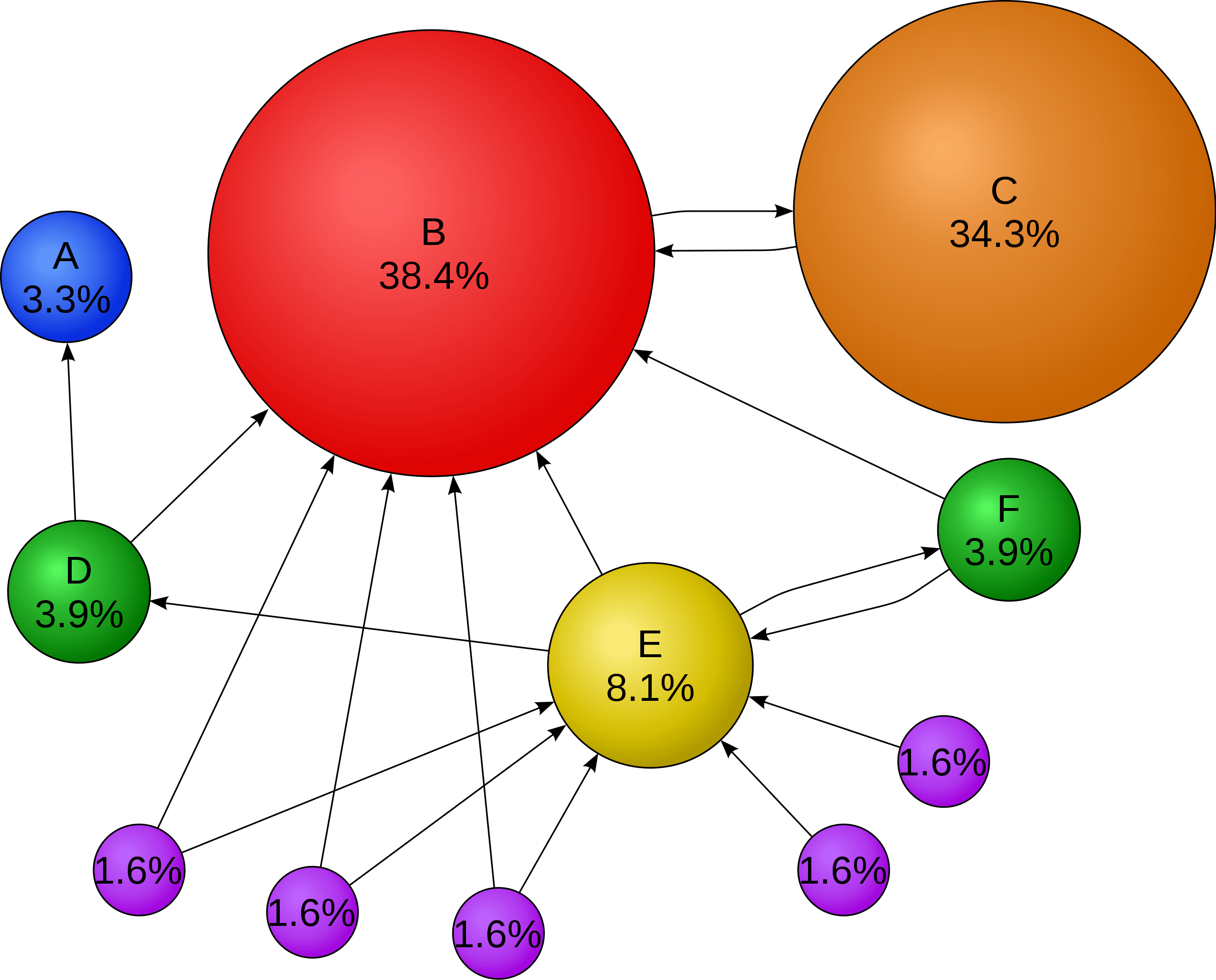
출처: https://en.wikipedia.org/wiki/PageRank
WWW : World Wide Web (웹은 거미줄)
웹사이트간의 링크를 조사하는 로봇? Crawler 혹은 Spider
Link 와 Anchor Text (Clickable Link)
거미줄 링크가 중요하면 어디서 부터 조사를 하나? 믿을 만한 웹사이트. 그럼 어떤게 믿을 만한 웹사이트인가? 어떻게 하면 객관적 판단하나?
Crawling, Indexing, Ranking
- 크롤링: 검색 엔진이 웹사이트를 조사했다
- 인덱싱 (색인): 검색 엔진이 검색 결과에 나올 준비가 되었다
- 랭킹: 검색 결과에 나온다. 순위에 잡힌다.
크롤링 -> 인덱싱 -> 랭킹
랭킹의 중요 요소 : Relevance & Importance (Citation) 예: 소셜미디어의 컨텐츠가 사람들이 좋아하는지 어떻게 판단하나? 좋아요, 댓글, 구독, 알림
그 Relevance와 Importance를 자동화 한 공식을 Algorithms 알고리즘이라고 합니다.
여러가지 알고리즘 요소 (Ranking Factors)가 있는데 이전에 올려 놓은 구글 검색엔진 최적화 요소들 확인 클릭, 구글 고급 명령어 확인하기 클릭
Spider/Crawler = software program = 감정이 없음 = 느낄 수 없고 읽을 수만 있음
웹페이지 설명
1. HTML <title>, meta keyword, and meta description tags
2. Semantic connectivity = 연관성 있는 단어들. 예를들어 "알로하"와 "하와이"

3. Reading level : 사용된 단어들의 연관성 혹은 길이, 문장의 길이 등등
4. 컨텐츠의 질 = 유일성 (Unique Contents?, Keywords?)
웹페이지의 질
Google Analytics 툴에서 보면 Bounce rate, Time on site, Page views per vistor
컨텐츠의 신선함? Freshness. 그래서 정통 구글 SEO 하는 사람들은 컨텐츠 업데이트에 힘을 쓴다.
링크의 질 (Link Analysis)
누가 웹사이트를 언급했으며, 뭐라고 언급 했나?
링크의 질은 어떻게 판단하나?
- Link neighborhood (어디서 왔나?)
- Anchor text (뭐라고 하나?)
Social Media Signals
소셜미디어에서 언급이 되었나?
결론
구글이 어떻게 작동하는지 이해해야 구글 SEO 작업이 가능합니다. 검색자들의 행동을 이해 하는 것을 넘어 구글 검색 엔진의 행동과 작동법을 이해합시다.